Dan Biderman
Dan Biderman
Home
Publications
Contact
CV
Light
Dark
Automatic
2
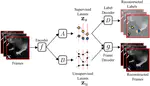
Partitioning variability in animal behavioral videos using semi-supervised variational autoencoders
This model disentangles movement that can be quantified by keypoints (e.g., limb position) from subtler feature variations like orofacial movements. We introduce a novel VAE whose latent space decomposes into two orthogonal subspaces – one unsupervised subspace and one supervised subspace linearly predictive of labels (keypoints). The latent space additionally includes a context variable that predicts the video/subject identity.
Matthew Whiteway
,
Dan Biderman
,
others
,
John P. Cunningham
,
Liam Paninski
PDF
Cite
Source Document
B or 13? Unconscious Top-Down Contextual Effects at the Categorical but Not the Lexical Level
Psychophysical presentation of ambiguous objects in context. Hierarchical Bayesian GLM and meta-analysis of subjects’ judgments.
Dan Biderman
,
Yarden Shir
,
Liad Mudrik
PDF
Cite
Code
Dataset
Source Document
Contingent Capture Is Weakened in Search for Multiple Features From Different Dimensions
A series of visual-serach experiments asking people to search for multiple features in parallel while ignoring distractors. The pattern of people’s attentional capture allowed us to characterize the cost of multi-tasking.
Dan Biderman
,
Natalie Biderman
,
Alon Zivony
,
Dominique Lamy
PDF
Cite
Source Document
Cite
×