Dan Biderman
Postdoctoral Scholar at Stanford Statistics & CS
Linderman Lab, Stanford Statistics
Hazy Research (Ré) Lab, Stanford CS
I am a Stanford Postdoc co-advised by Christopher Ré and Scott Linderman.
I build resource-efficient AI systems and apply them for neuroscience.
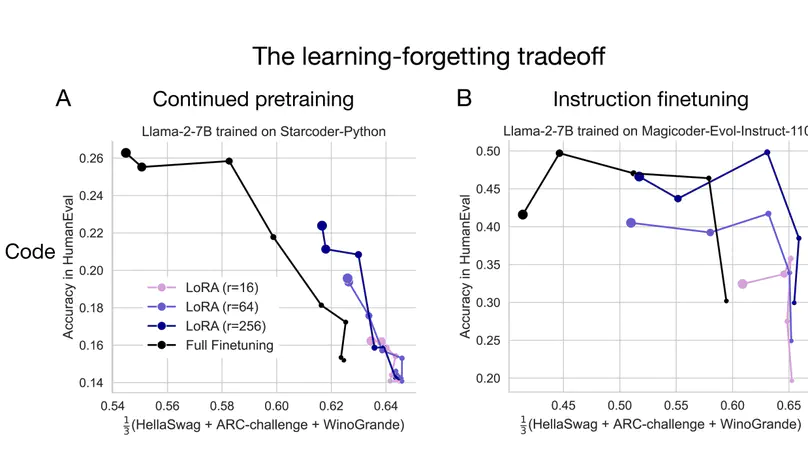
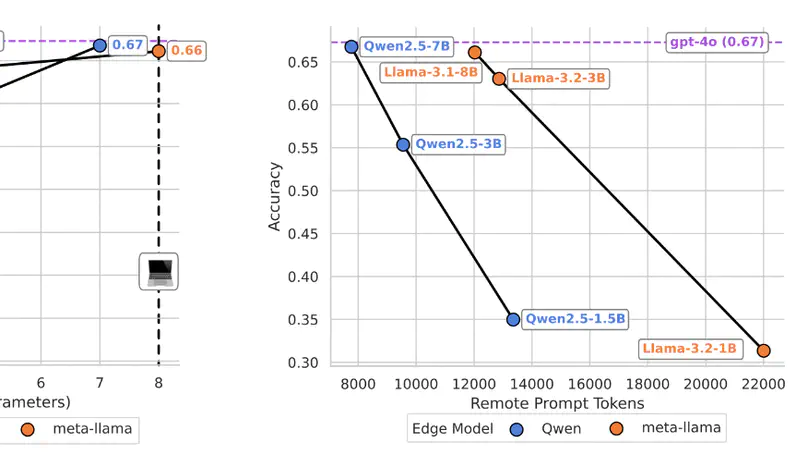
My current focus is on building language models that dynamically learn from experience. I recently shed light on learning-forgetting tradeoffs in parameter-efficient finetuning in colaboration with Databricks Mosaic AI (TMLR, 2024 (Featured Certification)), and proposed new collaboration patterns between on-device and cloud LLMs (see the Minions project, ICML 2025).
I co-organize the workshop on Efficient Systems for Foundation Models (most recently at ICML, 2025).
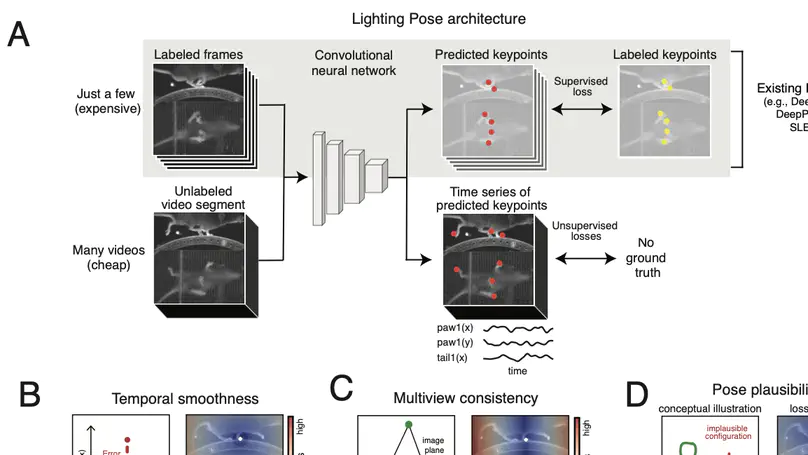
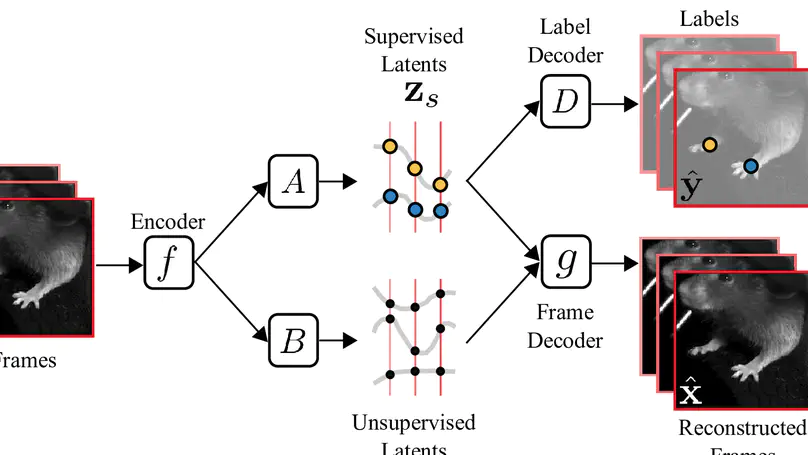
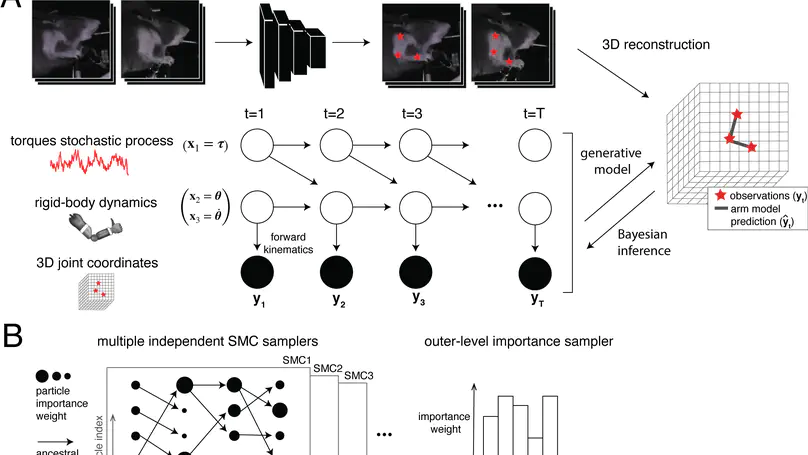
I graduated from a PhD at Columbia’s Center for Theoretical Neuroscience, where I worked with John Cunningham and Liam Paninski. In my main PhD project, I built deep learning models for tracking animal movement in videos - the Lightning Pose package (Nature Methods, 2024). I won Columbia’s Titus M Cowan dissertation prize in biomedical research, and served as the student speaker in the 2025 PhD hooding ceremony.
Here is my CV.
- Efficient LLMs and multi-agent systems.
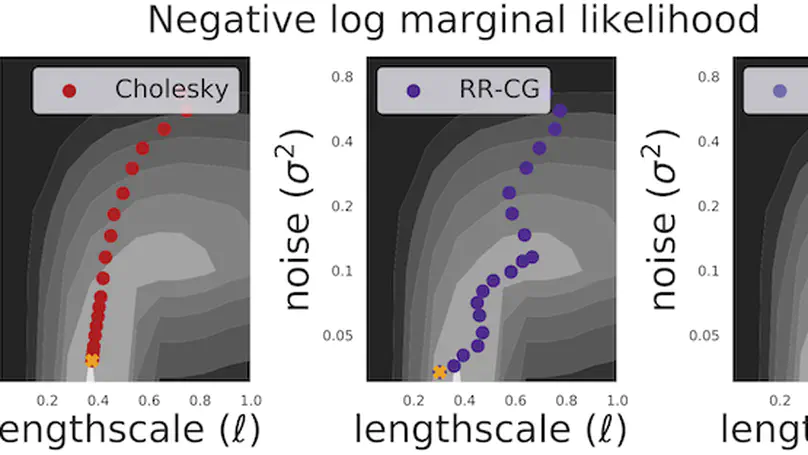
- Hardware-aware approaches to numerical linear algebra and ML.
- Modeling and analysis of biological data.
PhD in Computational Neuroscience, 2018-2024
Columbia University
MA in Cognitive Science, 2018
Tel Aviv University
The Adi Lautman Interdisciplinary Program for Outstanding Students (Cog. Sci., Math, Neurobio.), 2013-2017
Tel Aviv University